
L'intelligence de périphérie (Edge Intelligence) durable
L'accélérateur d'inférence pour l'IA de demain
L'intelligence artificielle - à la fois l'entraînement et l'inférence proprement dite - a jusqu'à présent été principalement développée pour les centres de calcul. Avec le nouveau domaine émergent de l'« intelligence artificielle de périphérie (IA Edge) », cette tendance est en train de changer. Smartphones, robots, drones, caméras de surveillance et caméras industrielles : dans un proche avenir, tous ces appareils intégreront une forme de traitement IA. Lorsque l'inférence doit avoir lieu directement sur les appareils d'imagerie eux-mêmes, les choses deviennent intéressantes. Comment une technologie aussi gourmande en performances peut-elle être utilisée de manière efficace et durable en dehors des grands centres de données, dans les petits appareils embarqués optimisés en ressources ? Il existe déjà des approches et des solutions fonctionnelles pour accélérer efficacement les réseaux de neurones sur les appareils en périphérie (Edge Devices). Mais rares sont celles qui sont suffisamment flexibles pour suivre le rythme rapide du développement de l'IA.
Intelligence en périphérie (Edge Intelligence)
En termes simples, la notion décrit une classe d'appareils capable de résoudre des tâches d'inférence à la périphérie de réseaux (« on-the-edge ») à l'aide de réseaux neuronaux et d'algorithmes d'apprentissage automatique. Dans ce contexte, une question se pose : pourquoi les appareils embarqués sont-ils destinés à recourir de plus en plus à l'intelligence artificielle et pourquoi l'industrie se focalise-t-elle désormais sur l'apprentissage profond et les réseaux de neurones profonds ?
Les réponses à cette question concernent moins l'IA elle-même que des sujets tels que la bande passante, les temps de latence, la sécurité ou le traitement décentralisé des données. Donc plutôt les problèmes clés et les défis auxquels sont confrontées les applications modernes de l'industrie 4.0. Une tâche importante consiste à réduire la concurrence inhérente sur la bande passante du canal de communication partagé en filtrant de grandes quantités de données de capteur ou de caméra sur les appareils périphériques (Edge Devices) eux-mêmes ou en les convertissant en informations exploitables. Le traitement direct des données permet également de prendre des décisions de processus directement à l'emplacement de la prise d'images sans la latence de la communication des données. D'un point de vue technique ou en matière de sécurité, il se peut même qu'une communication fiable et continue avec une unité centrale de traitement, peut-être même dans le cloud, soit difficile ou indésirable. Ce type d'encapsulation des données acquises sur les appareils en périphérie contribue également à la décentralisation du stockage et du traitement des données, et réduit ainsi la probabilité d'une éventuelle attaque sur l'ensemble du système. En effet, la sécurité des données générées et transmises est de la plus haute importance pour chaque organisation.
Une intelligence système distribuée crée également une séparation claire des tâches spécifiques à une commande. Par exemple, dans une usine, des centaines de postes de travail peuvent avoir besoin d'un service de classification d'images conçu de manière à analyser un ensemble différent d'objets sur chaque poste. Mais l'hébergement de plusieurs classificateurs dans le cloud a un coût. La solution à privilégier est une solution économique qui forme tous les classificateurs dans le cloud et envoie leurs modèles aux appareils en périphérie, c'est-à-dire une solution adaptée au poste de travail respectif. La spécialisation de chaque modèle fonctionne également mieux qu'un classificateur qui effectue des prédictions sur tous les postes de travail. En outre, les solutions spéciales simples, contrairement à la mise en œuvre du centre de données, permettent de réduire également le temps de développement si précieux. Tout cela plaide en faveur de l'externalisation de l'exécution des inférences vers les appareils en périphérie.
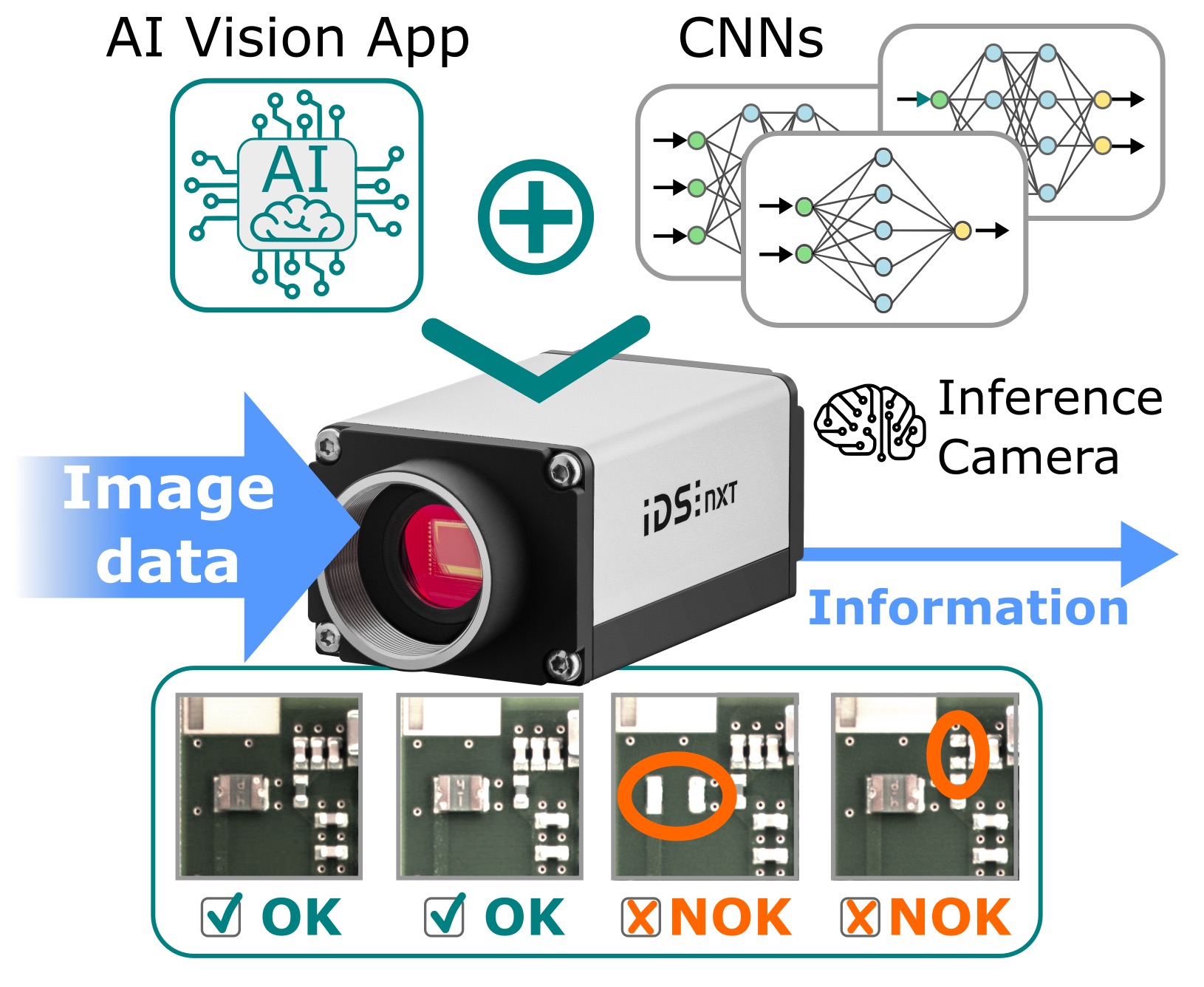
Figure 1 - Les appareils en périphérie intelligents permettent de réduire les énormes quantités de données de capteurs et d'image. Ils génèrent des informations directement utilisables en périphérie (on-the-edge) et ne les communiquent qu'à l'unité de commande.
Le défi
Pourquoi les réseaux de neurones sont-ils « réellement » inappropriés pour une utilisation intégrée ou quels sont les défis à relever pour les utiliser efficacement en périphérie (« on-the-edge ») ? Exécuter les tâches d'inférence d'IA sur des appareils en périphérie n'est pas si simple. Dans l'informatique en périphérie (Edge Computing), de manière générale, tout est une question d'efficacité. Les appareils en périphérie ne disposent le plus souvent que de ressources limitées en matière de calcul, de stockage et d'énergie. Les calculs doivent donc être réalisés avec un haut degré d'efficacité, mais doivent en même temps produire des valeurs de performance élevées, le tout avec des temps de latence faibles, ce qui semble incompatible. Avec l'exécution des CNN, nous avons également affaire à la discipline reine. Les CNN en particulier sont connus pour être extrêmement gourmands en ressources informatiques et nécessiter des milliards d'opérations pour traiter une entrée. Avec des millions de paramètres décrivant l'architecture CNN elle-même, en principe, ils ne sont pas un bon candidat pour l'informatique en périphérie (Edge Computing). Les réseaux dits « efficaces en termes de paramètres », comme MobilNet, EfficientNet ou SqueezeNet, dont la description nécessite un plus petit nombre de paramètres, conviennent pour une utilisation embarquée. Cela réduit considérablement les besoins en mémoire et les besoins informatiques. Mais ce n'est pas tout. Afin de réduire davantage les besoins de stockage, les réseaux doivent être compressés. Par exemple, les paramètres sans importance peuvent être supprimés après l'entraînement au moyen de l'élagage (pruning), ou le nombre de bits utilisés pour décrire les paramètres peut être réduit avec une quantification. La taille réduite de la mémoire du CNN a également un effet positif sur son temps de traitement. Et cela nous amène au dernier aspect de l'optimisation.
Malgré l'utilisation de réseaux compressés et efficaces en termes de paramètres, un système informatique adapté, spécialement personnalisé pour ces architectures, doit encore être utilisé pour permettre l'exécution efficace de l'IA en périphérie (on-the-edge). À cet effet, deux propriétés système de base doivent être considérées. En plus de l'efficacité déjà mentionnée, le système doit avoir suffisamment de flexibilité pour prendre en charge les nouveaux développements des architectures CNN. Ceci est important car chaque mois, en particulier dans le domaine de l'IA, de nouvelles architectures et de nouveaux types de couches quittent la zone de développement et de recherche. Ce qui est aujourd'hui actuel et nouveau peut être dépassé demain. Alors, quelles sont les options en matière de plateforme ?
Sélection de la plate-forme
- Un système basé sur le processeur offre sans aucun doute la plus grande flexibilité. En même temps, les processeurs sont malheureusement très inefficaces pour l'exécution des CNN et ne sont pas non plus très économes en énergie.
- Une plateforme GPU assure l'exécution des CNN avec beaucoup de puissance grâce à ses cœurs de calcul fonctionnant en parallèle. Bien qu'ils soient plus spécialisés que les processeurs, ils conservent une grande flexibilité. Malheureusement, les GPU sont très gourmands en énergie et donc plutôt problématiques en périphérie.
- L'architecture des FPGA programmables peut être reconfigurée sur le terrain et ainsi adaptée aux nouvelles architectures CNN. En raison de leur mode de fonctionnement parallèle, les FPGA ont également une grande efficacité. Cependant, leur programmation nécessite un niveau élevé de connaissances sur les matériels.
- Une solution ASIC complète, en tant que circuit intégré sur mesure, l'emporte haut la main en termes d'efficacité, car elle est spécifiquement optimisée pour exécuter efficacement une architecture CNN particulière. Cependant, la flexibilité peut être un problème si les architectures CNN nouvelles ou modifiées ne sont plus prises en charge.
Avec ses caractéristiques de « haute performance, de flexibilité et d'efficacité énergétique », l'utilisation de la technologie FPGA est la mieux adaptée à la réalisation d'un accélérateur CNN sur les appareils en périphérie au stade actuel du développement de l'IA.
La possibilité d'adapter cette technologie à tout moment pendant le fonctionnement de l'appareil en mettant à jour un nouveau fichier de configuration pour des applications ou des CNN spécifiques en fait une solution opérationnelle à long terme et qui convient donc à un usage industriel. Le principal défi dans le déploiement de la technologie FPGA est la grande complexité de la programmation, qui ne peut être effectuée que par des spécialistes.
Stratégie de développement
Pour mettre en œuvre des réseaux de neurones dans un « dispositif de vision périphérique » (Vision Edge Device), c'est-à-dire nos caméras IDS NXT, nous (IDS) avons décidé de développer un accélérateur CNN basé sur la technologie FPGA. Nous l'appelons « deep ocean core ». Cependant, afin de maintenir la gestion du FPGA aussi simple que possible lors de son utilisation ultérieure, il convient de développer une architecture universellement applicable, plutôt que plusieurs configurations spécialement optimisées pour différents types de CNN. Cela permet à l'accélérateur d'exécuter n'importe quel réseau CNN, à condition qu'il se compose de couches prises en charge. Mais, étant donné que toutes les couches régulières, telles que les couches de convolution, les couches d'addition, différents types de couches de pooling ou les couches squeeze-and-excite sont déjà prises en charge, en principe tous les types de couches importants peuvent être utilisés. Cela élimine complètement le problème de la complexité de la programmation, car l'utilisateur n'a pas besoin d'avoir des connaissances spécifiques pour créer une nouvelle configuration FPGA. Avec les mises à jour du micrologiciel de la caméra IDS NXT, le cœur « deep ocean core » est constamment mis à jour pour prendre en charge chaque nouveau développement dans le domaine des CNN.
deep ocean core
Comment fonctionne l'accélérateur CNN universel ou quelles mesures doivent être prises pour faire fonctionner un réseau neuronal formé ? L'accélérateur n'a besoin que d'une « description binaire » qui montre de quelles couches se compose le réseau CNN. Aucune programmation n'est nécessaire pour cela. Cependant, un réseau neuronal qui a été formé avec Keras, par exemple, utilise un « langage de haut niveau Keras » spécial que l'accélérateur ne comprend pas. Pour ce faire, il doit être traduit dans un format binaire qui ressemble à une sorte de « liste chaînée ». Chaque couche du réseau CNN devient un descripteur de nœud qui décrit précisément chaque couche. Finalement, une liste chaînée complète du CNN est créée en représentation binaire. L'ensemble du processus de traduction est réalisé automatiquement par un seul outil. Aucune connaissance particulière n'est requise non plus à cet effet. Le fichier binaire généré est maintenant chargé dans la mémoire de travail de la caméra et le cœur « deep ocean core » commence le traitement. Le réseau CNN fonctionne maintenant sur la caméra IDS NXT.
Flexibilité de l'exécution
L'utilisation d'une représentation du CNN sous forme de liste chaînée offre des avantages évidents en termes de flexibilité de l'accélérateur. Cela permet de basculer entre les réseaux à la volée. Et de manière transparente et sans délai. Plusieurs « représentations de listes liées » de différents réseaux neuronaux peuvent être chargées dans la mémoire de travail de la caméra. La sélection d'un CNN pour l'exécution nécessite que l'accélérateur deep ocean pointe vers le début de l'une de ces listes. Il suffit pour ce faire de modifier une « valeur de pointeur » pour désigner l'une des mémoires de la liste. Nous parlons ici d'un simple processus d'écriture d'un registre FPGA qui peut être exécuté très rapidement à tout moment.
L'exemple suivant explique pourquoi cette commutation rapide des réseaux CNN peut être importante. Supposons que vous avez une ligne de production sur laquelle sont fabriqués deux types de produits. Vous souhaitez contrôler la qualité des produits. Pour ce faire, vous devez d'abord reconnaître leur position, puis classer la qualité en fonction des défauts spécifiques au produit sur la base de la catégorie de produits reconnue.
Vous pourriez résoudre le problème en formant un grand réseau CNN à trouver les objets et à les classer en même temps, en pré-entraînant chaque cas de défaillance possible pour chacun des groupes de produits. C'est très complexe, et le réseau deviendrait très vaste et ne fonctionnerait peut-être que lentement, mais cela pourrait fonctionner. La difficulté ici sera d'atteindre un niveau de précision suffisamment élevé. Avec la possibilité de changer le réseau CNN actif à la volée, vous pourriez découpler la localisation et la classification des différents objets. Cela facilite la formation des différents CNN. La reconnaissance des objets n'a qu'à distinguer deux classes l'une de l'autre et fournir leurs positions. Deux autres réseaux sont formés uniquement sur les propriétés et les classes d'erreur respectives spécifiques au produit. Suivant le produit localisé, l'application caméra décide alors de manière entièrement automatique quel réseau de classification est activé en conséquence afin de pouvoir également déterminer la qualité respective du produit. Grâce à cette approche, l'appareil en périphérie travaille sur des tâches relativement simples avec peu de paramètres. En conséquence, les réseaux individuels sont également beaucoup plus petits, doivent différencier beaucoup moins de caractéristiques et sont donc plus rapides et moins gourmands en énergie, ce qui les rend parfaitement adaptés à une exécution sur un appareil en périphérie.

Figure 2 - La possibilité de modifier l'exécution des réseaux de neurones à la volée permet de décomposer l'analyse d'image en flux de travail d'inférence plus simples qui sont plus efficaces, plus rapides et plus stables sur la caméra.
Performant et efficace
L'accélérateur CNN basé sur FPGA fonctionne dans nos caméras d'inférence IDS NXT sur un SoC Xilinx Zynq Ultrascale avec 64 cœurs de calcul. Dans de nombreux réseaux de classification d'images connus, tels que MobileNet, SqueezeNet ou EfficientNet, des fréquences d'images allant jusqu'à 67 images par seconde sont atteintes. Même sur les familles de réseaux telles que ResNet ou Inception, jugées trop complexes pour l'informatique en périphérie (Edge Computing), une fréquence de 20 images par seconde est possible, ce qui est tout à fait suffisant pour de nombreuses applications. La mise en œuvre du FPGA nous permet aussi de développer davantage les performances de l'accélérateur deep ocean. Toutes les caméras déjà sur le terrain bénéficient des mises à jour du micrologiciel.
Dans le domaine de l'informatique en périphérie (Edge Computing), cependant, l'efficacité énergétique est un élément encore plus important. Elle indique le nombre d'images par seconde qu'un système peut traiter par watt d'énergie. Cela fait de l'efficacité énergétique une bonne mesure pour comparer différentes solutions de périphérie. Le diagramme suivant compare divers accélérateurs CNN : le deep ocean core en tant qu'implémentation FPGA, la solution GPU avec un Jetson TX 2A, la solution CPU classique avec un processeur Intel Core-i7 actuel, un Raspberry Pi en tant que solution CPU embarquée et une solution entièrement ASIC, représentée par la puce IA Intel Movidius.

Figure 3 - Pour les réseaux efficaces en termes de paramètres notamment, tels les MobilNets ou SqueezeNet, l'architecture FPGA est clairement gagnante. Elle a le rendement énergétique le plus élevé parmi les systèmes comparés. Cela fait du noyau deep ocean le candidat préféré pour l'intelligence Edge.
Solution de caméra d'inférence complète
Pour faciliter encore davantage l'utilisation de l'accélérateur CNN basé sur FPGA, IDS propose une solution de caméra d'inférence complète qui rend la technologie facilement accessible à tous. Pour former et gérer un réseau neuronal, les utilisateurs n'ont pas besoin de connaissances spécialisées en apprentissage profond, en traitement d'image ou en programmation de caméra ou FPGA. Ils peuvent s'atteler immédiatement au traitement d'image basé sur l'IA. Des outils conviviaux éliminent les obstacles, permettant de créer des tâches d'inférence en quelques minutes et de les exécuter immédiatement sur une caméra. En plus de la plateforme de caméra intelligente IDS NXT équipée de l'accélérateur CNN basé sur FPGA « deep ocean core », le concept global inclut un logiciel de formation facile à utiliser pour les réseaux neuronaux. Tous les composants sont développés directement par IDS et conçus pour fonctionner ensemble de manière transparente. Cela simplifie les processus de travail et rend le système global très efficace.
L'intelligence de périphérie (Edge Intelligence) durable
Les différentes possibilités de mise en œuvre de réseaux de neurones mentionnés dans l'article ont chacune des avantages et des inconvénients propres. Si les utilisateurs finaux doivent gérer eux-mêmes les composants nécessaires pour utiliser l'IA dans les tâches de vision industrielle, ils emploient volontiers des accélérateurs d'IA entièrement intégrés, tel l'Intel Movidius. Les solutions de puces prêtes à l'emploi fonctionnent efficacement, permettent d'obtenir des prix unitaires réservés normalement aux grosses quantités et peuvent être intégrées rapidement et assez facilement dans les systèmes grâce à une documentation complète de la gamme de fonctions. Mais il y a un « hic ». Leur longue période de développement est malheureusement un problème dans le contexte de l'IA qui a pris un élan considérable et évolue quotidiennement. Aujourd'hui, développer une « intelligence de périphérie » (Edge Intelligence) fonctionnant de manière universelle et flexible nécessite que les composants du système répondent à d'autres exigences. Une base FPGA correspond à la combinaison optimale entre flexibilité, performances, efficacité énergétique et durabilité. Car l'une des principales exigences pour un produit industriel est sa « compatibilité industrielle », qui est assurée, entre autres facteurs, par une longue disponibilité et une facilité de maintenance à long terme. La plate-forme de caméra d'inférence conviviale IDS NXT associée à un accélérateur FPGA-CNN représente une solution d'intelligence de périphérie complète et durable avec laquelle les utilisateurs finaux n'ont plus à se soucier des composants individuels et des mises à jour de l'IA.
Informations complémentaires
- Sur le site Web du produit, vous en apprendrez davantage sur la plateforme d’IA de vision embarquée IDS NXT.
- Dans l'article technique « L'IA pour tous », vous en apprendrez davantage sur la manière simple de vous initier à la technologie du deep learning grâce à la solution de caméra d'inférence tout-en-un IDS NXT Experience Kit.

M. Heiko Seitz, ingénieur diplômé, travaille chez IDS depuis 2001. Après avoir travaillé pendant plusieurs années en tant que développeur dans le domaine des logiciels pour caméras, il soutient aujourd'hui la communication technologique chez IDS en tant que Product Marketing Manager. Fort de son expérience, il fait le lien entre une technologie complexe et un transfert de connaissances axé sur la pratique, par exemple dans des articles spécialisés, des webinaires ou des conférences.
Vision Channel
Vidéos et sessions en direct autour de la vision industrielle.
Votre projet
Comment pouvons-nous vous aider dans votre projet ? Ensemble, nous trouverons la solution qui vous convient !
Bulletin d'informations
Restez informé en vous abonnant à notre newsletter.